TL;DR Most startups deploy AI and then wrap approval layers around every output, humans checking, reviewing, signing off. The intention is control. The result is a bottleneck that consumes exactly the productivity gains AI was supposed to deliver. A growing body of peer-reviewed research shows that indiscriminate human oversight introduces automation bias, inflates review workloads, and degrades the team judgment it was meant to protect. This article explains why the trap works the way it does, what the data says, and what the operational fix actually looks like.
What Is the Human-in-the-Loop Model and Why Did Everyone Default to It?
Human-in-the-loop (HITL) is a design pattern in which a human reviewer is inserted at one or more points in an AI-driven workflow. AI produces an output, a human validates it, then it moves forward.
In theory, this combines machine speed with human judgment. In practice, most startups applied it as a blanket policy rather than a calibrated decision, and that distinction is where the productivity collapse begins.
The adoption logic was reasonable at the time. Early AI outputs were inconsistent. Regulators began requiring human accountability for automated decisions. Founders were cautious about trusting systems they couldn't fully audit. HITL felt like the responsible default.
The problem is that "responsible default" became "universal requirement"; applied not just to high-stakes, irreversible decisions where it belongs, but to every AI-generated output regardless of its risk profile. When that happens, AI doesn't remove bottlenecks, it relocates them downstream, into your review queue, where they quietly compound.
The Productivity Promise vs. the Productivity Reality
The gap between how much founders expect AI to accelerate their teams and what actually happens at the operational level is now measurable, and the numbers are worse than most people have absorbed.
In a randomized controlled trial published on arXiv in July 2025, researchers from METR studied 16 experienced developers completing 246 real tasks using Cursor Pro with Claude 3.5/3.7 Sonnet. Before the study, developers predicted AI would reduce their completion time by 24%. After completing it, they estimated a 20% reduction. The actual measured result:
AI tooling increased completion time by 19%. The developers were slower with AI than without it.
What makes this finding important is not the number itself, it's the perception gap. The developers believed AI was helping them. The mechanism is predictable once you understand it:
AI accelerates the part of the work that feels like work, generating output, while the validation, correction, integration, and review that follows expands to absorb the gains.
Research by Faros Engineering confirms the pattern at scale. Individual developers completed 21% more tasks when using AI coding tools. But review time increased 91%, because teams were generating 98% more pull requests. The productivity gains did not disappear, they were transferred into the review layer, where they sat waiting for a finite number of human eyes.
AI didn't make those teams faster. It made their bottleneck less visible.
What This Looks Like in Practice: A Content Team Scenario
Picture a twelve-person startup with a content and support function that has integrated AI across three workflows:
- drafting customer-facing documentation
- generating first-pass support replies
- producing internal product briefs
On paper, the team looks productive. AI drafts are ready in minutes and the output volume has doubled. Leadership points to it as a clear AI win.
Under the surface:
every draft is routed to a human reviewer before it goes anywhere. The documentation lead approves documentation. The support manager reviews every AI reply before it reaches a customer. The product lead signs off on every brief. Each of these people now spends 60-90 minutes per day on AI review that didn't exist six months ago.
Check the acceptance rate. It's 94%. For every hundred AI-generated outputs, six get modified. The other ninety-four go through untouched, after consuming the reviewer's time, attention, and context.
That is not oversight. That is latency with extra steps.
The team hasn't gained capacity. They've shifted capacity from creation to approval and called it AI adoption.
Why Human Review Doesn't Reliably Catch AI Errors
Human review doesn't improve AI output quality the way founders assume it does. In most workflow contexts, it creates the appearance of a quality gate without functioning as one. The reason is structural, not motivational and understanding the structure is what makes it fixable.
When a human reviews an AI-generated output, they are not evaluating it from a neutral starting point. They encounter the output after the AI has already framed the problem, selected the information presented, and structured the conclusion.
The reviewer's job, at that point, is to find fault with an argument that has already been assembled for them. That is a fundamentally different cognitive task than producing the judgment independently, and it is a task humans perform poorly, consistently, across domains.
A 2025 systematic review in AI & Society (Springer Nature), examining 35 peer-reviewed studies across healthcare, finance, national security, and public administration, confirms this pattern:
Humans agree with incorrect AI recommendations at significant rates, and standard mitigation attempts don't help. Providing multiple explanation formats made no difference. Trust calibration feedback made no difference. Simplistic explanations, the kind most startup tools provide, made reviewers more vulnerable to incorrect AI outputs, not less.
The second layer of the problem runs deeper. Human-AI feedback loops don't just fail to correct bias, they actively amplify it. Research published in Nature Human Behaviour (Glickman & Sharot, 2024) found that human-AI interactions amplify bias more than human-human interactions do.
The reviewer is not a check on the system. They are part of the system, and the system bends their judgment without them noticing.
This is why the 94% acceptance rate in the scenario above is not a sign of a team doing its job well. It is a sign of a team that has been absorbed into a feedback loop it thinks it is controlling.
You can't outsource judgment to a review step that automation bias has already compromised.
The Automation Bias Trap: Confident in the Wrong Direction
Here is what is actually happening when your support manager reviews the ninety-fourth AI reply of the week:
they are not evaluating it. They are pattern-matching it against the previous ninety-three and approving it because it looks the same. The review step exists on paper. The scrutiny does not.
This is automation bias, not carelessness, not incompetence, but a predictable cognitive response to working alongside automated systems at high frequency. When outputs are mostly correct and the task volume is high, scrutiny degrades. The reviewer's brain optimizes for throughput. It has to.
What makes this particularly damaging in startup workflows is the non-linearity of the failure mode. Research by Horowitz and Kahn, published in International Studies Quarterly (Oxford Academic, 2024), found that humans are overconfident in AI under routine, lower-stakes conditions, and swing to algorithm aversion, rejecting even correct AI outputs, when stakes feel high.
Most startup workflows live permanently in the first category:
high-frequency, lower-stakes decisions that train reviewers to approve, so that when the genuinely consequential output arrives, the habit is already set.
The deeper consequence is skill degradation. The ability to catch an AI error requires domain competence, the kind that comes from doing the work independently, not from approving outputs someone else assembled. The more often your team validates rather than creates, the less capable they become at the one thing your review process depends on.
The oversight mechanism becomes less reliable precisely because it is used so frequently. That is the trap closing.
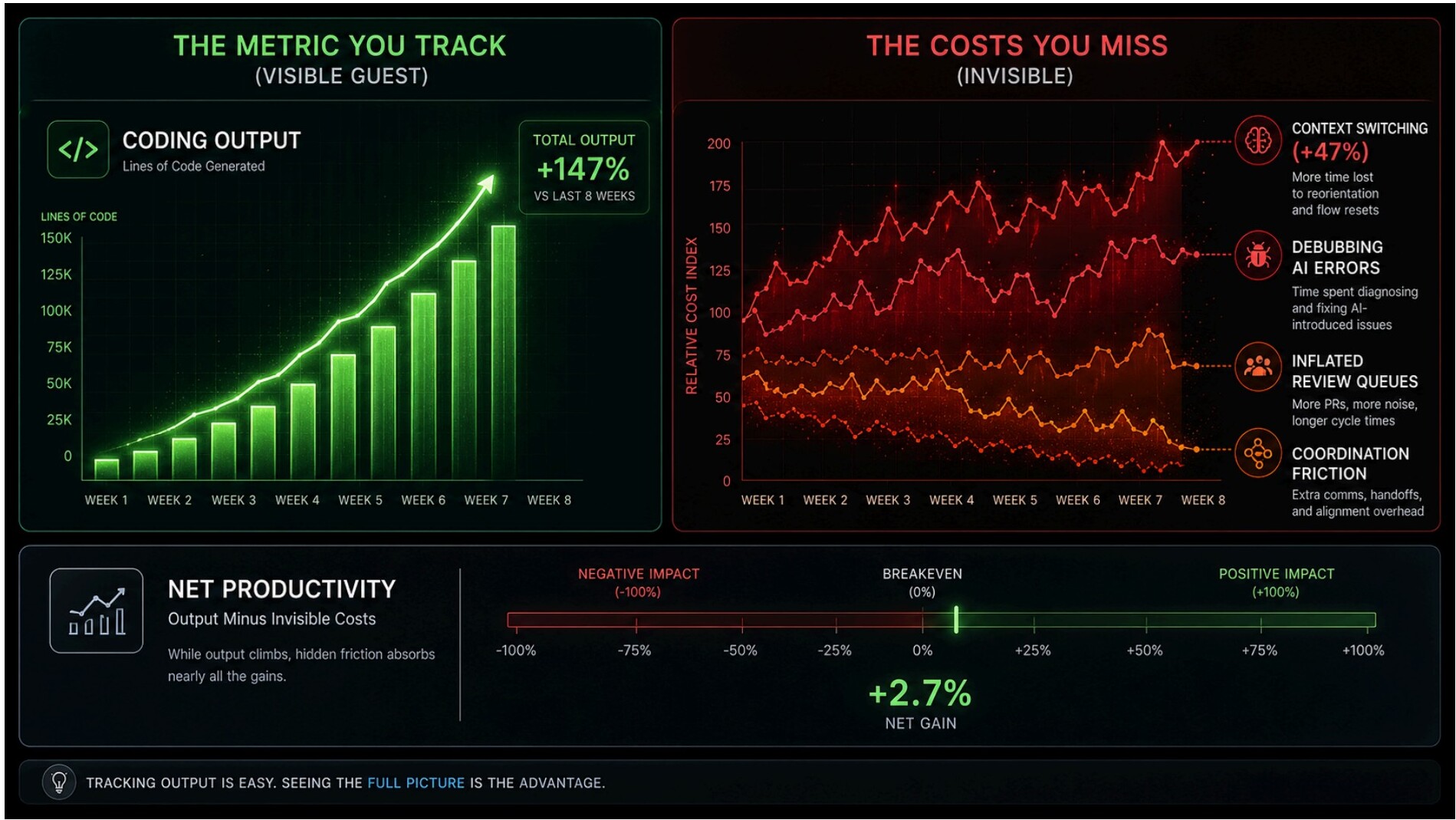
The Real Cost: Where the Time Goes and Why It Stays Hidden
Most founders measure AI productivity at the point of output generation, the only place gains are immediate and attributable. The cost distributes itself across the review, correction, integration, and coordination layers that follow, and it accumulates in places that don't show up in the dashboard.
Writing code occupies approximately 30% of a developer's time. The other 70% is review, meetings, debugging, testing, and coordination. If AI cuts the coding portion in half, the theoretical productivity gain is around 15%, but only if the remaining 70% stays constant. Faros Engineering found that context switching increases 47% when developers use AI intensively, as parallel workstreams multiply. The 15% gain is absorbed before it reaches the bottom line.
The Stack Overflow 2025 Developer Survey found that positive sentiment toward AI tools dropped from over 70% in 2023-2024 to 60% in 2025. Forty-six percent of developers distrusted AI accuracy. As experience accumulates, the invisible costs, debugging AI-generated errors, managing inflated review queues, recovering from context switches, erode what the initial adoption felt like.
The productivity loss is real. It just doesn't appear on the metric you're tracking.
What the EU AI Act Clarifies About Appropriate Oversight
The EU AI Act, enforceable for most obligations from August 2026, establishes a risk-tiered framework for human oversight that is instructive even for companies outside EU jurisdiction. High-risk AI systems, in credit scoring, employment, education, law enforcement, critical infrastructure, require documented human oversight mechanisms. Lower-risk applications do not carry the same requirements.
The regulatory logic mirrors the operational one:
oversight intensity should scale with consequence severity. The Act implicitly rejects blanket HITL as a compliance strategy, because blanket HITL is not risk management, it is bureaucracy that creates the appearance of control without the function of it.
The illusion of control is more dangerous than no control. At least no control forces you to be honest about where the risk actually is.
A Practical Framework for Getting Out of the Trap
The fix is not removing humans from consequential decisions, but it is auditing where your current review requirements actually sit on the risk-consequence spectrum, and being honest about what that review is delivering.
1. Classify your AI workflows by decision profile.
For each workflow, ask four questions. Is the output irreversible or costly to reverse? Does it carry regulatory or legal accountability? Does it affect external stakeholders directly? Is the AI's error rate in this domain unknown or known to be high? Workflows that score high on any of these dimensions warrant structured human review. Workflows that score low across all four are candidates for trust-with-monitoring.
2. Measure your actual acceptance rate.
If your reviewers are approving AI outputs without modification at a rate above 90%, the review is not functioning as quality control, it is functioning as latency. Remove mandatory review from those workflows. You are not eliminating oversight; you are eliminating theater.
3. Introduce statistical sampling rather than universal review.
For medium-risk, high-frequency workflows, shift from reviewing 100% of outputs to reviewing a randomized 10-15%. This preserves your ability to detect systematic errors and drift without consuming proportional human time. Most quality issues are patterns, not one-off events, sampling finds them faster than exhausted reviewers reviewing everything.
4. Build rollback, not approval.
For low-risk outputs, auto-ship with a rollback mechanism rather than a pre-approval step. The cost of a bad output in most of these contexts is lower than the accumulated cost of reviewing every output. Shift your oversight posture from pre-emptive to responsive.
The operational heuristic:
"If you can fix an error after the fact in under ten minutes, you probably shouldn't require human approval before the fact at all."
The Productive Version of Human-in-the-Loop
Human oversight of AI is not a mistake. Applied to the right decisions, irreversible, high-stakes, externally consequential, legally accountable, it is one of the most important risk management tools available.
The research is not arguing against human judgment, it is arguing against applying human judgment to contexts where it adds friction without adding accuracy.
The startups that are operating efficiently with AI in 2026 are not the ones who removed humans from their workflows. They are the ones who stopped treating "a human checked this" as the definition of safety, and started asking what checking it actually costs, and what it actually catches.
Most startups aren't using HITL as risk control. They're using it as a crutch, a way to feel in control of systems they don't fully trust, in exchange for the productivity gains those systems were supposed to deliver.
If your reviewers are approving 90% of outputs unchanged, they are not protecting you. They are just the last place your bottleneck lives before you notice it.
The question worth sitting with is not "should humans be in this loop?" The question is:
"what would you have to believe about this AI output, and your reviewer, for that review step to be worth it?"
Answer that honestly for each workflow you run, and the architecture writes itself.
Resources
- METR, "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity", arXiv, July 2025: arxiv.org
- Romeo & Conti, "Exploring Automation Bias in Human-AI Collaboration: A Review and Implications for Explainable AI", AI & Society, Springer Nature, July 2025: link.springer.com
- Glickman, M. & Sharot, T., "How Human-AI Feedback Loops Alter Human Perceptual, Emotional and Social Judgements", Nature Human Behaviour, 2024: doi.org
- Horowitz, M.C. & Kahn, L., "Bending the Automation Bias Curve: A Study of Human and AI-Based Decision Making in National Security Contexts", International Studies Quarterly, Oxford Academic, June 2024: academic.oup.com
- Agudo, U. et al., "The Impact of AI Errors in a Human-in-the-Loop Process", Cognitive Research: Principles and Implications, PubMed, January 2024: pubmed.ncbi.nlm.nih.gov
- Beck, J. et al., "Bias in the Loop: How Humans Evaluate AI-Generated Suggestions", arXiv, September 2025: arxiv.org
- Stanford HAI, "The 2025 AI Index Report", Stanford University Human-Centered Artificial Intelligence, 2025: hai.stanford.edu
- Mahlow, P., Züger, T. & Kauter, L., "KI unter Aufsicht: Brauchen wir 'Humans in the Loop' in Automatisierungsprozessen?", HIIG Digital Society Blog / Humboldt Institute for Internet and Society, 2024: hiig.de
- TDWI, "The Role of Human-in-the-Loop in AI-Driven Data Management", September 2025: tdwi.org
- National Institute of Standards and Technology (NIST), "Artificial Intelligence Risk Management Framework (AI RMF 1.0)", U.S. Department of Commerce, 2023: nist.gov